AirOpsEngine
Azure Data Factory | Databricks | Delta Lake | Azure ADLS Gen2 | Azure Key Vault|Github
Project Overview:
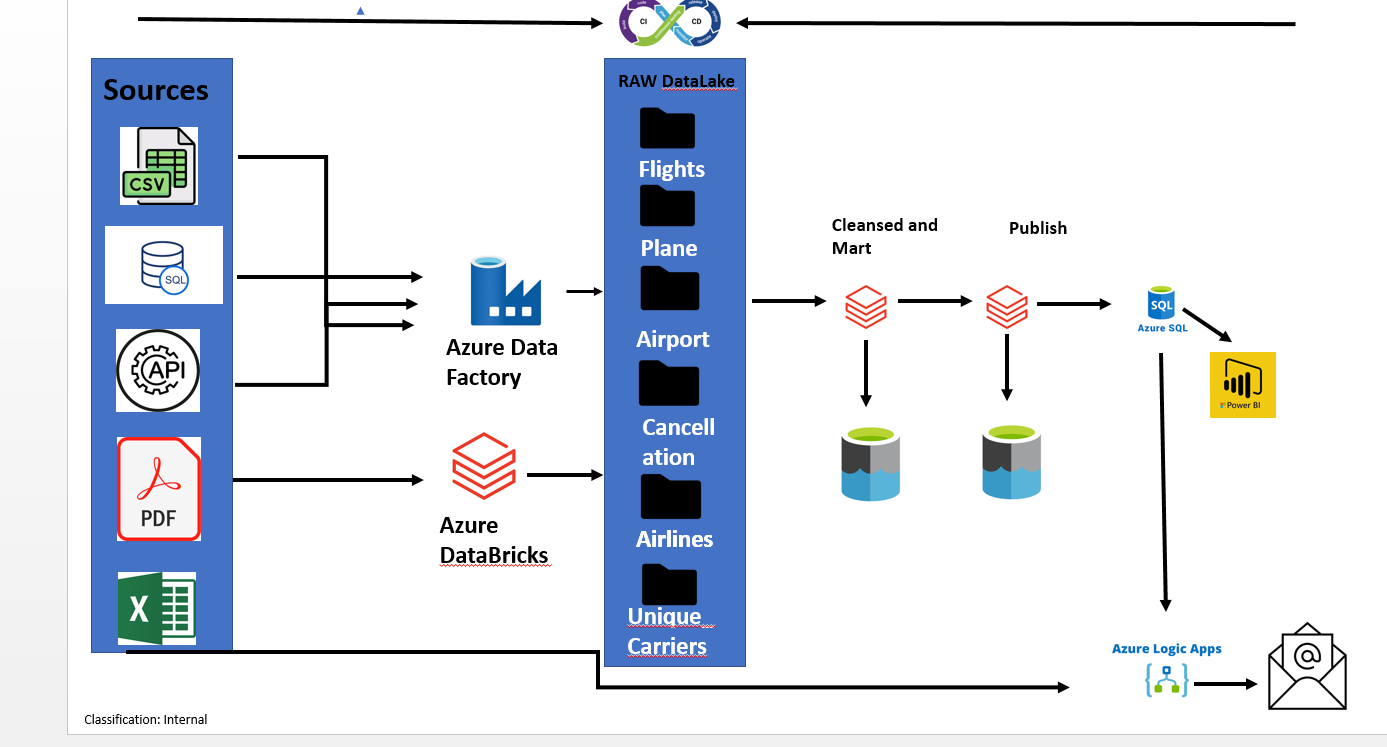
This project aims to build a data pipeline which is scheduled and triggered by Azure Data Factory for historical and up-to-date Airlines data. Datafactory, Databricks,Azure keyvault,Azure datalake gen2 ,Azure logic app, and Delta Lake were used to implement a solution .
The data was obtained from different sources. From airlines API ,SQL database and from cloud storage and subsequently tailored to suit the requirements of the project. Following this, the data was stored in DataLake Azure ADLS Gen2 and did the necessary transformation and was then saved in both Delta Lake and Azure SQL Database. Using data factory and databricks, data must be ingested transformed into tables for reporting and analysis, and made available for reporting and copy to Azure SQL database.Data pipelines must be scheduled, monitored, and alerts set up for pipeline failures.
Detail codes can be found in my Github repository here
Project Requirements:
1. Data Ingestion Requirements
The task is to load historical Arlines data from various sources into data lake Azure ADLS Gen2 and for all of that and apply the appropriate schema to the data.The source data comes in various formats like csv,json,API,sql data and pdfs. The ingested data must be made available for various workloads Additionally, the ingestion logic must be designed to handle incremental data loads.
2. Data Transformation Requirements
TThe requirements include combining required data items into transformed table for reporting/analysis purposes, and storing the transformed data in Delta format and also to data marts.The transformed data must be made available for various workloads, such as machine learning, BI reporting, and SQL analytics. Finally, the transformation logic must be designed to handle incremental loads.
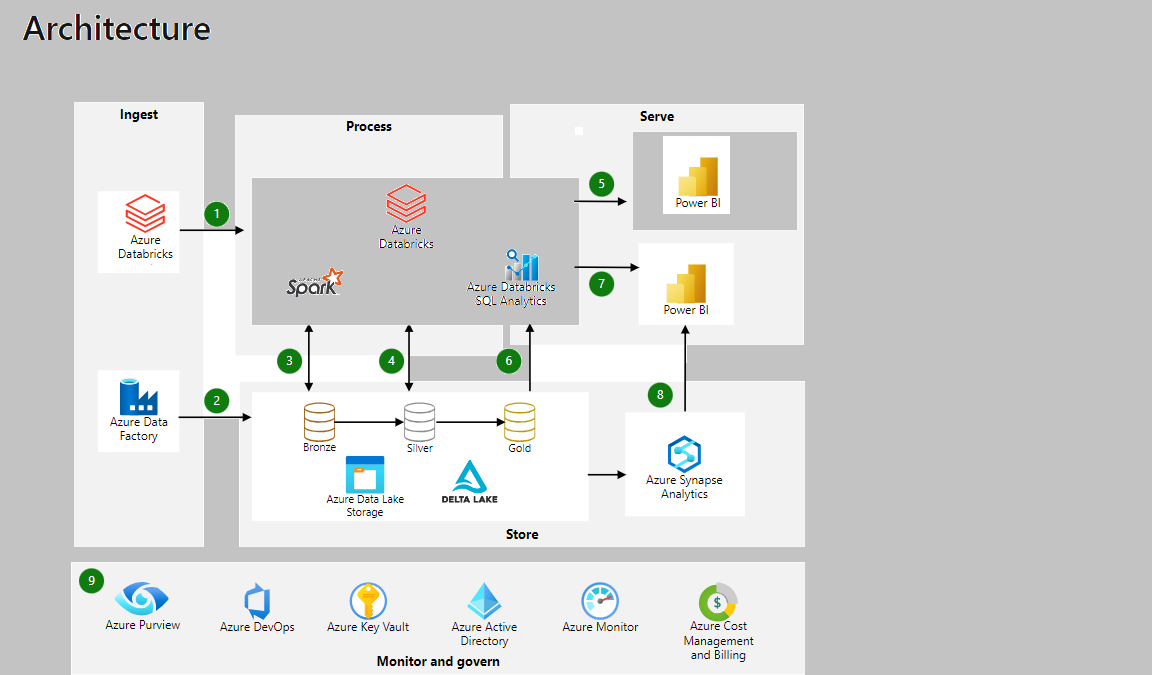
Solution Architecture:
The architecture includes three layers: the raw layer(Bronze layer), the processed layer(Silver layer), and the presentation layer(or Gold layer). Data will be uploaded to raw layer in csv/json/pdf/parquet format and ingested using Databricks Notebooks before being stored in the processed layer in delta format. The processed layer will include schema and partition information Transformed data will be stored in the presentation layer in Delta format. Azure Data Factory will be used for orchestration, scheduling and monitoring the pipelines. The below image represents the solution architechture for this project: